Abstract
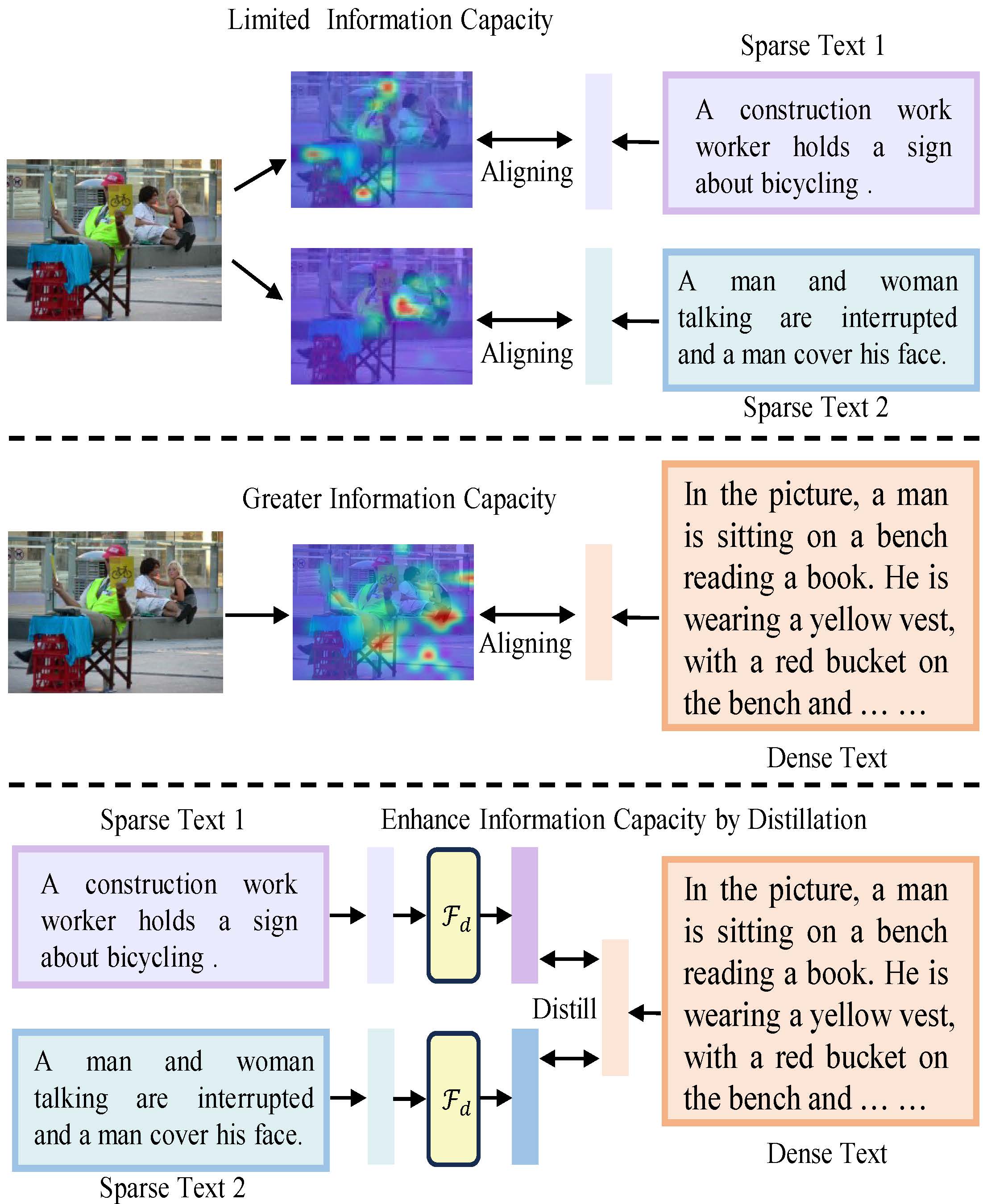
Enabling Visual Semantic Models to effectively handle multi-view description matching has been a longstanding challenge. Existing methods typically learn a set of embeddings to find the optimal match for each view's text and compute similarity. However, the visual and text embeddings learned through these approaches have limited information capacity and are prone to interference from locally similar negative samples. To address this issue, we argue that the information capacity of embeddings is crucial and propose Dense-to-Sparse Feature Distilled Visual Semantic Embedding (D2S-VSE), which enhances the information capacity of sparse text by leveraging dense text distillation. Specifically, D2S-VSE is a two-stage framework. In the pre-training stage, we align images with dense text to enhance the information capacity of visual semantic embeddings. In the fine-tuning stage, we optimize two tasks simultaneously, distilling dense text embeddings to sparse text embeddings while aligning images and sparse texts, enhancing the information capacity of sparse text embeddings. Our proposed D2S-VSE model is extensively evaluated on the large-scale MS-COCO and Flickr30K datasets, demonstrating its superiority over recent state-of-the-art methods.
Code/Pre-trained Models
Our code and pre-trained models are available on our Github repo.Citation
@InProceedings{liu2025aligning,
author = {Liu, Yang and Feng, Wentao and Liu, Zhuoyao and Huang, Shudong and Lv, Jiancheng},
title = {Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025}
}